SwiftUIのプレビューがうまくいかない時はカラー定義を見直してみよう
これはなに?
SwiftUIで開発をしていると開発初期はプレビューを使い効率的に開発ができていたのですがコード量が増えたとたんプレビューが表示されなくなりました。
どういったコードを書くとプレビューが表示されなくなるのか気になったので調べてたものです。
開発環境
- Xcode12.3
- MacOS BigSur 11.0.1
どういったコードを書くとダメなのか
デフォルトで定義されているカラーを extension で上書き使用するとプレビューが動かなくなります。
import SwiftUI struct ContentView: View { var body: some View { Text("Hello, world!") .foregroundColor(.primary) .padding() } } struct ContentView_Previews: PreviewProvider { static var previews: some View { ContentView() } } extension Color { static let primary = Color("Primary") }
プレビュー画面
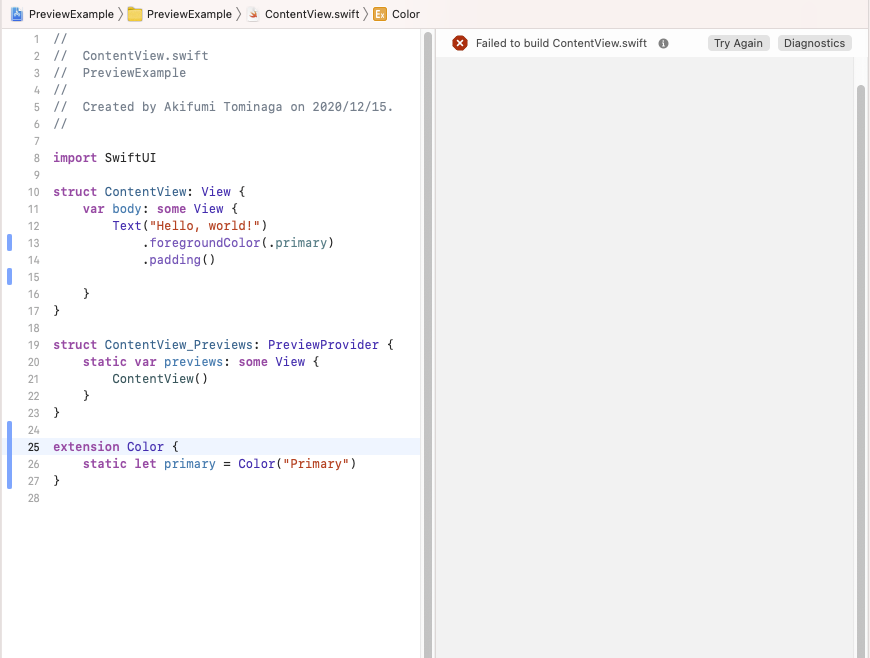
他にも .white , .black などがあります。今回サンプルに使った .primary というプロジェクト内のカラー定義で使いたい名前もデフォルトで定義されています。
独自カラーは割り切ってプロジェクト名をPrefixにつけて色を管理すると被りづらくプレビューを使ったまま開発ができて良いと思います。
iOSのプロジェクトに入ったらやること
SwiftでのiOSアプリ開発の仕事を請けることが多いのですが、 プロジェクトの初期や、途中から入った時に最初にやっておいた方がいいことを自分の備忘録としてまとめてみた。
- Bitriseへの移行
- dSYMのアップロード自動化
- テスト自動化
- TestFlight配布の自動化
- デプロイ自動化
- swiftlintの導入
- swiftlintのルール管理
- fastlane match での証明書管理
- 開発版と本番を端末上に共存できるようにする
- 開発版と本場のFIrebaseを分ける
- Firebase Crashlytics でのクラッシュレポート
- Firebase App Distribution での 開発版/本番アプリ配布
- Firebase Performance の導入
- Dynamic Links での起動
- APNsをFirebase経由にする
- storyboard と ViewController を1対1にする
- Swift バージョンアップ
- 強制アップデート
- Associated Domainsの設定
KVS(Key Value Store)における履歴データのキー設計
目次
- これは何?
- 履歴データのキー設計
- この設計をしない方が良いケース
- まとめ
これは何?
大量のデータを扱うようになったためDynamoDBやFirestoreなどのKVSを扱う機会が増えています。KVSであるDynamoDB、Cloud Firestore、Cloud Bigtableで大量データになりがちな履歴データの設計をする機会があったのでその時に考えた設計をまとめたもの。


履歴データのデータ設計
この記事で扱う履歴データとは、会員のログイン履歴や、行動履歴のような「時間+何らかのデータ」を新しい順 or 古い順に保持する時系列データのことを想定しています。
KVSにおいてまず最初に考えることは、「Keyを何にするか」だと思います。
KVSのKeyの特徴として大抵の場合、データはKeyの辞書順に並びます。(例えば、keyが a, 1, 2 という3つのデータがあった場合、ソートを指定せずに取得を行うと、1, 2, a という順番でデータが返ってくるということ)
この特性を使って履歴データを扱う際は、
のようにするとソートされた状態でデータを格納することができます。
これによりソートの指定をする必要がなくなり、複合Indexの設定を減らすことができる。
また、タイムスタンプだけでデータの登録をすると、データベースによっては読み込み&書き込みが一部のデータに偏りホットスポットができてしまうという問題があります。 親となるデータのID+タイムスタンプのようにすると処理するデータを分散し管理することができます。
データを絞り込んで表示したい場合は、DBによりクエリの指定方法は変わりますが文字列比較を行うKeyだけで絞り込むことができます。(Candidate_20200701 ≦ id < Candidate_20200801だと2020年の7月のデータを取得できる)
この設計はしない方が良いケース
時系列を使った絞り込みやソートを使わないケースでは、キーを有効活用できなくなるためこの設計はせずにデータの特性に合わせてキー設計をした方が良いです。
まとめ
- 履歴データを管理する際はTimestampを利用したキー設計にすると絞り込み、ソートが簡単に行える
- Prefixつけることでホットスポットになりづらいキー設計をすることができる
- 時系列で扱わない場合は別のキー設計にした方が良い
iPhoneアプリを実機確認するためのApple Developerの証明書更新
目次
- これは何?
- 登録方法
- 証明書更新
- まとめ
これは何?
iPhoneアプリ開発をする際に、実機を使った動作確認をすると思います。AppleDeveloperにIDが登録されているアプリの場合、AppleDeveloperへの端末登録や証明書の更新など手間がかかったので手順をまとめてみました。
端末登録
Apple Developerへの端末登録時に、実機ビルドする端末のUUIDを取得する必要があります。
確認をするにはXcodeのDevicesから確認をすることができます。


これをApple DeveloperのDevicesに登録をしてください。



証明書更新
Apple DeveloperのCertificates, Identifiers & Profilesから追加したProfileを選択します。
Profileの編集を押下するとDevicesが表示されるので、先ほど追加したDeviceを追加しましょう。
https://developer.apple.com/account/resources/profiles/list
これで追加が完了しました。
各開発者がそれぞれProfileの更新をすれば新しい端末でテストを行うことができます。
まとめ
iPhoneアプリを開発するときは、実機で確認するだけでも結構手間がかかりますね。
fastlane を使えばいろいろ自動化することができますが次の機会にまとめたいと思います。
HomebrewでMacの初期設定を効率化する
目次
- なぜこの記事を書いたのか
- 効率化するためにやっていること
- まとめ
なぜこの記事を書いたのか
昨年から職場が変わったり支給されているPCが変わったりでMacの初期設定をする機会が4回ほどありました。
使っているアプリをすべて探してダウンロードすると普通に1日潰れてしまうので、2回目から自動化をはじめました。
今回はその自動化方法をまとめました。
効率化するためにやっていること
dotfilesレポジトリを作成する
自分のPC設定をするためのレポジトリを1つ作成します。
こちらはプライベートレポジトリでも、パブリックレポジトリでもいいと思いますが、機密情報を扱う場合はプライベートにしておきましょう。
シェルの設定 dotfiles に追加する
エンジニアなら、bashの設定なら .bashrc zshなら .zshrc に記述していると思います。
こちらを先ほど作成した dotfiles に追加をしましょう。
他にも vimユーザーなら .vimrc tmux は .tmux.conf の設定をしていると思うので一緒に管理しておくと楽です。
使うファイルをBrewfileでインストールする

一番時間がかかるのがMacないのアプリで使っているものを探してダウンロードする作業だと思います。
homebrew を使ってインストールしているアプリを管理することができるのでその機能を使います。
この機能を使うことでコマンド1つですべてのアプリケーションをダウンロードすることができます。
簡単なサンプル
tap "homebrew/core" tap "homebrew/bundle" tap "caskroom/cask" brew "zsh" brew "peco" brew "tmux" brew "git" brew "jq" cask "iterm2" cask "visual-studio-code"
PCセットアップ用のシェルスクリプトを用意する
シェルの設定は dotfiles に移動すると使えなくなってしまうのでシンボリックリンクを作成する必要があります。
毎回コマンドを思い出して実行するのは面倒なのでセットアップようのシェルスクリプトを作成していると便利です。
以下に簡単なサンプルを作成しておきます。
ln -s ~/dotfiles/.zshrc ~/.zshrc ln -s ~/dotfiles/.vimrc ~/.vimrc ln -s ~/dotfiles/.gitconfig ~/.gitconfig ln -s ~/dotfiles/.tmux.conf ~/.tmux.conf brew bundle
新しいPCでやること
ここまで用意できたら新しいPCでやることは簡単です。
作成したレポジトリをcloneして、そのレポジトリないでシェルスクリプトを実行するだけです。
git clone https://github.com/xxxx/dotfiles.git cd dotfiles sh ./xxxx.sh
まとめ
Brewfileや.zshrcの管理を行うことでPCの初期設定を自動化できました。IT業界にいると定期的にPCを変えることになると思うので、変更する機会があったら自動化にチャレンジしてみると良いと思います。
GCP Firestore: データの関係性ごとに適当な設計を考えた
目次
- なぜこの記事を書いたのか
- Firestore とは
- 設計について
- まとめ

なぜのこの記事を書いたのか
直近一年間に GCP の Datastore, Firestore, AWS の DynamoDB など色々なKVSを触る機会に恵まれました。 もともとRDBを使っていたため最初はKVSの設計にかなり戸惑ってしまいました。 これから使う人の参考になればと思い、データの関係性ごとにどう設計すれば良いのか今の考えをまとめました。
Firestore とは
Firestore は、柔軟でスケーラブルなリアルタイム データベースです。プロトタイプを迅速に作成できるだけでなく、どのような規模の開発にも対応できるスケーラビリティと柔軟性を兼ね備えています。 Firestore はリアルタイム データベースであるため、クライアントは Firestore のデータをリッスンして、変更が生じたときにはリアルタイムで通知を受け取ることができます。この機能により、ネットワーク レイテンシやインターネット接続に関係なく動作する応答性の高いアプリを構築できます。
設計について
1:1 のデータ
基本的に1対1のデータは1つのドキュメント(RDBでいうレコード)に保存する RDBと違ってSchema定義も必要なく、1つのドキュメントで1 MiBまで保存できるのでほとんど気にすることはないと思います。
ただ、RDB違って Field を指定して取得することができないため、 住所やパスワードといった機密情報を別のユーザーが取得できるとセキュリティの問題があるため、 別の Collection に保存し、セキュリティグループで本人のみデータを取得できるように制約をかけることを検討した方が良いです。
1:N のデータ
Nに上限がある場合
1つのドキュメントに配列として保存した扱うとドキュメントの取得する数を減らせてコスト削減できるため1つのドキュメントにまとめることをおすすめします。
ただ、Nのデータ単体で表示したりソートをする必要がある場合は扱いにくいため別のCollectionにすることを検討すると良いと思います。
Nに上限がない場合
1 MiBの制限に引っかかる可能性があるためSubCollectionや別のCollectionに分けて保存する必要があります。 別Collectionにする場合、毎回1のデータを取得しなくても済むように、データのコピーをNのデータに持つことを検討すると良いです。
以下のようなイメージです
purchase
{
"price": "number",
"count": "number",
"purchased_at": "timestamp",
"user": {
"id": "string"
"name": "string"
"address": "string"
"phone_number": "string"
}
}
以下ようにするとN+1クエリが発行されたり、クライアントでデータをくっつける必要が出てきて非効率になるため、 仕様上問題がなければ非正規化した方が良いと思います。
purchase
{
"price": "number",
"count": "number",
"purchased_at": "timestamp",
"user_id": "string"
}
N:N のデータ
N対Nの場合は、1ドキュメントでは表現できないため基本的に複数の Collection を使うことになります。
基本的には新しく関係性を表現するCollectionを作成すると良いと思います。
shops_tags
{
"shop_id": "string",
"shop_name": "string",
"tag_id": "string",
"tag_name": "string"
}
ただ、シンプルに記述したくて利用頻度が多くない場合は、どちらかにもう片方の配列を保持することでも実現しても良いと思います。
shops
{
"name": "string",
"tags": [
{
"id": "string",
"name": "string",
},
{
"id": "string",
"name": "string",
}
]
}
まとめ
- Firestoreの設計をするときに最初に検討した方が良いことをまとめました。
- RDBとは考え方が違うので最初は非常に戸惑うと思います。
- データの関係性ごとにどう設計するかまとめたので最初は参考にして設計すると良いと思います。
ネット上の記事や、ドキュメントを色々みましたが、以下の動画がかなり参考になったので一度みてみると良いと思います。 www.youtube.com
トラックポイント付きのメカニカルキーボード Tex Yoda Ⅱ を使ってみた
HHKBを購入してからずっと使っていたのですが、 キー配列が特徴的でMacbookのキーボードで作業をするときに打ち間違えが多くなったことや、 元々ThinkPadキーボードを使っておりトラックポイントの良さを忘れられず、 いろいろ調べていたところTexYodaが非常に気になっていました。
ただ価格がHHKB並みにしますし、最近キーボードを買ったばかりで悩んでいたため、 Twitterで軽い気持ちでTextYoda気になるとのツイートをしたところ友人が貸してくれることになりました。

先週末にお借りして、月曜日の仕事から使い始めてみました。 2,3日使ってみたところ、 トラックポイントは横スクロールもでき満足しています。 感度が良すぎるという人も結構いますが、元々トラックポイントのスクロールスピードを最大にしていたので、私にはちょうどよかったです。
キータッチについては、茶軸のスイッチのものを使っています。 HHKBと比べるとうち心地は少し悪いかなーと思いますが、元々静電容量方式に強いこだわりがあるわけではなかったので概ね満足しています。 茶軸だと少し重い感じがするので、私には赤軸の方があってそうです。ここは個人的な好み
不満をあげるとすれば、f1などのキーをfnキーとのコンビネーションで入力する必要があるのですが、 この配列がHHKBと違いすぎるため慣れるのに時間がかかりそうです。
キーのリマップの自由度が高いことと、キーキャップをカスタムオーダーサイトもあるので、 気に入らない人は自分でカスタマイズすると良いと思います。 https://yoda2.tex-design.com.tw/
総じて、 トラックポイント付きのキーボードの中では非常に良いキーボードだと思いました。 ただ、一方で最近発売されたThinkPadキーボードも気になっているところではありますw